Bootcamp Finale & Whisper Experiments
Buenas, todos! It’s the very last day of the 6-week AI Builders Bootcamp I’ve been taking, led by the enviably articulate and insightful Shawhin Talebi. I just dropped my last message to the peer group I’d volunteered to lead throughout the course.
Bootcamp Finale 🪶
“Hello hello everyone! Can hardly believe today is the last session for the bootcamp — it flew by like the 5-hour data limit window before Claude boots you out 😂
This week, I focused on a tiny fine-tuning experiment — more about shoring up my understanding of foundation models than producing anything polished. Since I plan to make hands-free accessibility central to future projects, I worked with the open-source automatic speech recognition (ASR) model Whisper. What a time to be alive that these models are available as a baseline! By the second epoch, Whisper had already outpaced my little CNN model that was learning from scratch.
I wanted to fine-tune Whisper on a key voice marker I designed for an “AI reading/voice notes partner” (a week-3 project), but the dataset is still way too small. The big lesson this week: fine-tuning’s bottleneck is almost always the dataset. While I didn’t land a real fine-tuned application, I now have a clearer sense of what a fine-tuning plan would need.
Outside the bootcamp bubble, I overheard a fascinating conversation at a coffee shop between folks from a mission-driven design agency (Partner & Partners). They were debating whether tracking time helps or just adds overhead, when someone joked, “Isn’t AI supposed to handle that for us?” …at which point I swooped in 😅 Hoping to follow up with them, hear more about their pain points, and maybe sketch out a business-requirements doc as practice. Besides, I’m genuinely interested in tinkering some AI systems to help with time-tracking, even just for myself! I’m also curious: have any of you tinkered with AI for time-tracking yet?
It’s been such a pleasure learning alongside you all these past weeks. I’ll be bouncing between Madrid, Columbia (South Carolina), and Sao Paulo this year, so reach out if your travels overlap! In particular, if you’re in Madrid (or know someone there who’d like to chat), let me know, as that is the long-term destination goal, and I currently know zero Madrileños. In the meantime, let’s keep in touch on LinkedIn or email. And I promise I’m not intentionally a sneaky conversation creeper 😄”
Automatic Speech Recognition - Hands-Free Accessibility 🤲
If you’re interested in the pedagogical notebook I mentioned in my last bootcamp post, you can find it here: 👉 Automatic Speech Recognition Fine-Tune vs. CNN from Scratch
ASR is absolutely central to my interest in hands-free accessibility with tech. …And hands-free accessibility is central to my AI dev ideas because:
-
wow, arthritis, way to truncate that post-carpal tunnel bliss!
-
as if m typos arent bda eougnh arlaedy, I can’t imagine them surviving the baby-cradling, toddler-chasing chapters of my life.
Whisper—trained on 680,000 hours of multilingual data by OpenAI—is already remarkably capable: it processes mel-frequency representations that approximate how humans perceive speech, and captures most utterances with striking fidelity.
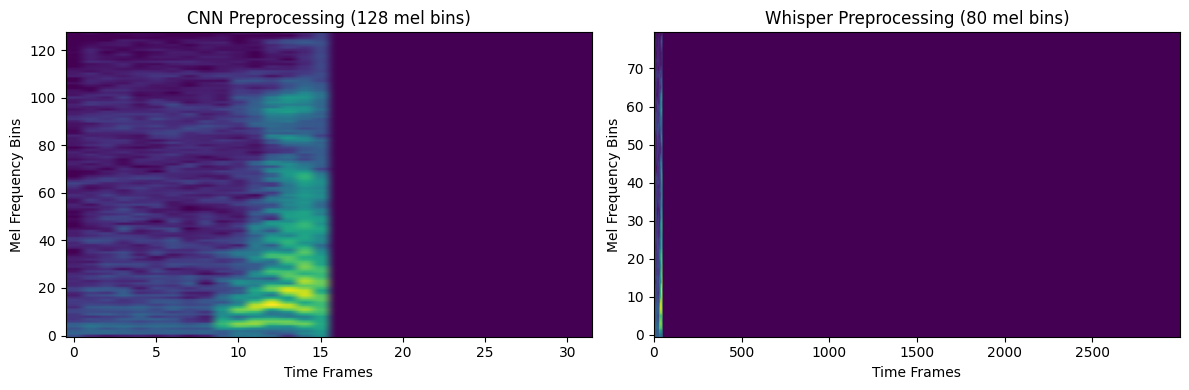 FIG. A: While CNN treats all frequencies equally, Whisper has learned to emphasize the frequency ranges where human vocal information is concentrated–hence the narrower, more focused band.
FIG. A: While CNN treats all frequencies equally, Whisper has learned to emphasize the frequency ranges where human vocal information is concentrated–hence the narrower, more focused band.
But fine-tuning remains crucial, as I show in the notebook. Inevitably, bias emerges through the training data—Whisper’s corpus leans heavily toward polished presentation speech, often in English, often by fluent speakers.
So what happens when a voice doesn’t fit those statistical norms? Be it someone new to English, someone who prefers not to speak English, someone just learning to speak at all (hello, lil’ tot 🐣)…or someone who just ran out of rods to spin another plate and just needs to ramble a bit 🫣. In those last cases, the ellipses and marginalia may actually carry the most signal.
Precursor to the Fine-Tuning Experiment: Saluda AI 📚
I first explored this transcription challenge with Whisper back in Week 3 of the bootcamp. The experiment was to develop an AI that remembers your book reactions and uses them to inform its responses—whether for brainstorming or emotional processing. I recorded myself reading passages that struck me and then riffed with a few thoughts.
Voluble I might be, but emotions feel slipperier than dream memory. I suspect Reason is really a combination of logic and sentiment. So I wonder: what personal emotional texture might our smarty-pants AI kin infer when I nerd out about books, rather than try so hard to “feel”? A very preliminary POC lives here: 👉 Saluda Cognitive Fingerprinting (POC)
But “Saluda AI” is a story for another time, alongside the many other experiments I cobbled together during this bootcamp journey.
As for time-tracking AI—nothing to recommend just yet (for the design agency of which I am now an honorary meeting member 😅). But! If you’re looking for a time management solution for diving into the AI sandbox, Shaw’s bootcamp is one expertly structured place to start. 🗺️